
eBay Kleinanzeigen is the largest C2C marketplace in Germany and we’re growing at an amazing pace. With more than 20 million monthly users and over 28 million live ads, thousands of interactions take place every second. Originally, our platform was very search-focused - our personalised home feed aims to provide whole new experience on top of that, inspiring our users with hidden gems on our platform, tailored just to them.
So, what’s the problem, and why is it hard?
Lots of data - and still growing
To present our users with a feed of interesting items, we need to find a way to learn about what they’re actually interested in. A natural place to start is with what users are searching for and what they’re looking at on our platform. On a platform as large as ours, this means hundreds of searches and thousands of items viewed per second. Given that we’re still experiencing massive growth of inventory and users, it’s vital that we can accommodate this.
Finding interesting items
We have over 28 million items in our inventory at any given time. By analyzing our users’ behaviour on our platform, we can figure out what they are interested in, but we still need to use that somehow to select the best few out of those millions of items.
Occasional visitors
Additionally, we have many occasional visitors. In fact, a big part of our user base hasn’t been active in the last 30 days, and might decide at any time to come back and look for something new - like racing bikes. With the risk of losing them again for a long time, it’s crucial for us that we capture their interest right in that moment, with our feed ideally reflecting it instantly.
Short-lived inventory
To make matters more challenging, we’re also dealing with very short-lived inventory, and each posted item on our site usually corresponds to a single physical item. Why is this a problem? At any moment a user requests the feed, many of the items may no longer be there, especially when we’re dealing with rare or popular objects. Since the last thing we want to do is annoy our users by dangling unobtainable carrots in front of them all the time, it’s important that we show them fresh and live inventory as much as possible.
Experimentation and continuous improvement
At eBay Kleinanzeigen, we put a lot of focus on lean development and experimentation. As such, we want a system that allows us to start simple, yet enables us to iterate and continuously improve upon our logic.
What does all of this mean for our system? We need something that can process our users’ interactions with our platform in real-time, while providing a way to use that information to distill a feed of items that are relevant, yet still fresh — and we need to do it in a way that accommodates our growth, and allows for constant change.
Now that we have set the stage, let’s first have a look at some of the other players and how they have solved similar problems.
Feed building - what about the giants?
With more and more platforms making personalised home feeds the default landing experience for their users, two general approaches have emerged:
(1) Precalculating a feed for each user, either using batch jobs or in a more event-driven fashion as new items come in. This was done in the Twitter feed and the earlier implementations of the Pinterest feed and the LinkedIn Feed. It supports fast retrieval of feeds at read time and more complex ranking models in the background. However, there are downsides: plenty of feed materializations might be wasted as they remain unseen by the user; it’s also not trivial to groom the feeds in terms of item expiry, ranking algorithm changes and A/B testing. Depending on the processing speed, the feed might not feel real-time enough to wow and inspire users.
(2) Calculating a user’s feed on demand only, which is a concept followed by the more recent LinkedIn and Pinterest feed implementations. This abandons offline ranking pipelines and storage dedicated to materialized feeds, but the architectural benefits come at the expense of response times and stronger restrictions on ranking complexity.
For us, the on-demand calculation clearly seems the better fit with the eBay Kleinanzeigen characteristics described earlier. Let’s look closer at technologies that suit our requirements:
Kafka Streams: Solving real-time user profiling
Given the continuous nature and sheer amount of data that we have to store per user, a streaming solution seemed promising. Rather than sifting through huge amounts of data periodically, streaming allows us to incrementally update what we know about our users immediately as they are interacting with our system. Since we’re already using Kafka, it made sense to store these user interactions (like item views and search actions) in Kafka topics for later processing. As such, it was only natural to give Kafka Streams a go as our streaming solution.
Kafka Streams has a few more properties that made it a compelling tool for us: its scalable nature and the fact that it doesn’t require a specialized cluster. The scalability comes from the underlying technology of Kafka itself which is designed for (and proven to) scale, and those properties extend to Kafka Streams. It doesn’t require a specialized cluster because you include it as a library dependency in your application, and it runs and deploys within your existing infrastructure.
We use Kafka Streams to calculate several user features that help us personalize the feed. Among them are the top locations that users seem to be interested in, derived from the location of the items they view. Similarly, we calculate a user’s favorite categories derived from the categories of the viewed items. Another source of input are the users’ searches which we store in recency order.
Kafka Streams allows us to update these user features in near real-time, while providing an easy way to scale out and accommodate our platform’s continuous growth. The next piece of the puzzle is how we use these user features to select the best ones out of millions of live items.
Elasticsearch: Solving short-lived items & ranking flexibility
Now how do we pick the right content to show in the personalized feed?
We established earlier that we need an on-demand system that’s able to turn user features into a ranked list of items. For that, another technology in our company’s toolbox is a great fit: Elasticsearch. It’s a scalable, distributed search engine that powers eBay Kleinanzeigen’s core search and comes with a great set of searching and ranking options. Elasticsearch allowed us to run a range of experiments with different queries and rankings generated from various user features, to iteratively improve on our feed. A selection of ranked queries we built is:
- Using Elastic’s “More Like This” query to find items similar to a user’s last viewed items
- Retrieving new items for past searches by re-running past search queries
- Find trending items near a user’s location
- Find new items in a user’s favorite or “next best” categories
Results of these queries are then weighted and mixed to provide the items as a personalized feed.
Resulting system
We ended up with a reasonably simple setup that can be operated and scaled by developers on existing infrastructure. Here’s a simple overview with two parts:
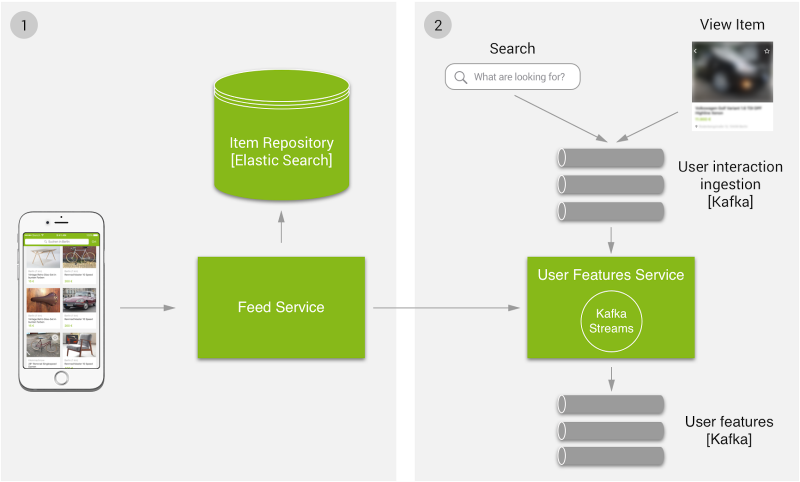
(1) At query time, user features are retrieved and used to query our item repository. The features are (2) continuously aggregated from user interactions that flow into the Kafka Streams application. Both parts of the system consist of microservices that can be scaled independently and on-demand.
This also allows us to quickly implement and deploy new ideas. We can separately create A/B tests on the query building side, or on the user feature side.
Final thoughts
We designed a straightforward system serving thousands of personalised feeds per second. With the chosen technologies, we are confident that we can continue to scale.
One remaining concern is the Elasticsearch cluster: even with its inherent scalability, having 20 parallel queries executed every time a user requests a page in their home feed requires a big cluster, and — with a growing number of users and features — is something we need to keep an eye on.
However, this can also be seen as the price to pay for an on-demand architecture. From a product perspective, on-demand is very desirable, and so far it suited all of our product ideas. While precalculated feeds would bring a strong performance benefit at query time, that approach shifts the complexity elsewhere. It would require that feeds are calculated and maintained for the entire user base and it is questionable whether that scales better in the long run.
Regardless of the scalability issues that we see on the horizon, we are still very happy with our setup as it currently solves our product needs and provides the flexibility and speed we need to iterate and improve on our feed.
By the way, we’re hiring ;)